AI tools for llm onnx
Related Tools:

None
I am sorry, but the provided text does not contain any information about a website or AI tool. Therefore, I cannot generate the requested JSON object.

Every AI
Every AI is an AI software that offers over 120 AI models, including ChatGPT from OpenAI and Anthropic/Claude, for a wide range of applications. It provides incredible speeds and access to all models for a subscription fee of $20. The platform aims to simplify AI development at scale by offering developer-friendly solutions with extensive documentation and SDKs for popular programming languages like Ruby and JavaScript.

LLM Clash
LLM Clash is a web-based application that allows users to compare the outputs of different large language models (LLMs) on a given task. Users can input a prompt and select which LLMs they want to compare. The application will then display the outputs of the LLMs side-by-side, allowing users to compare their strengths and weaknesses.
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.
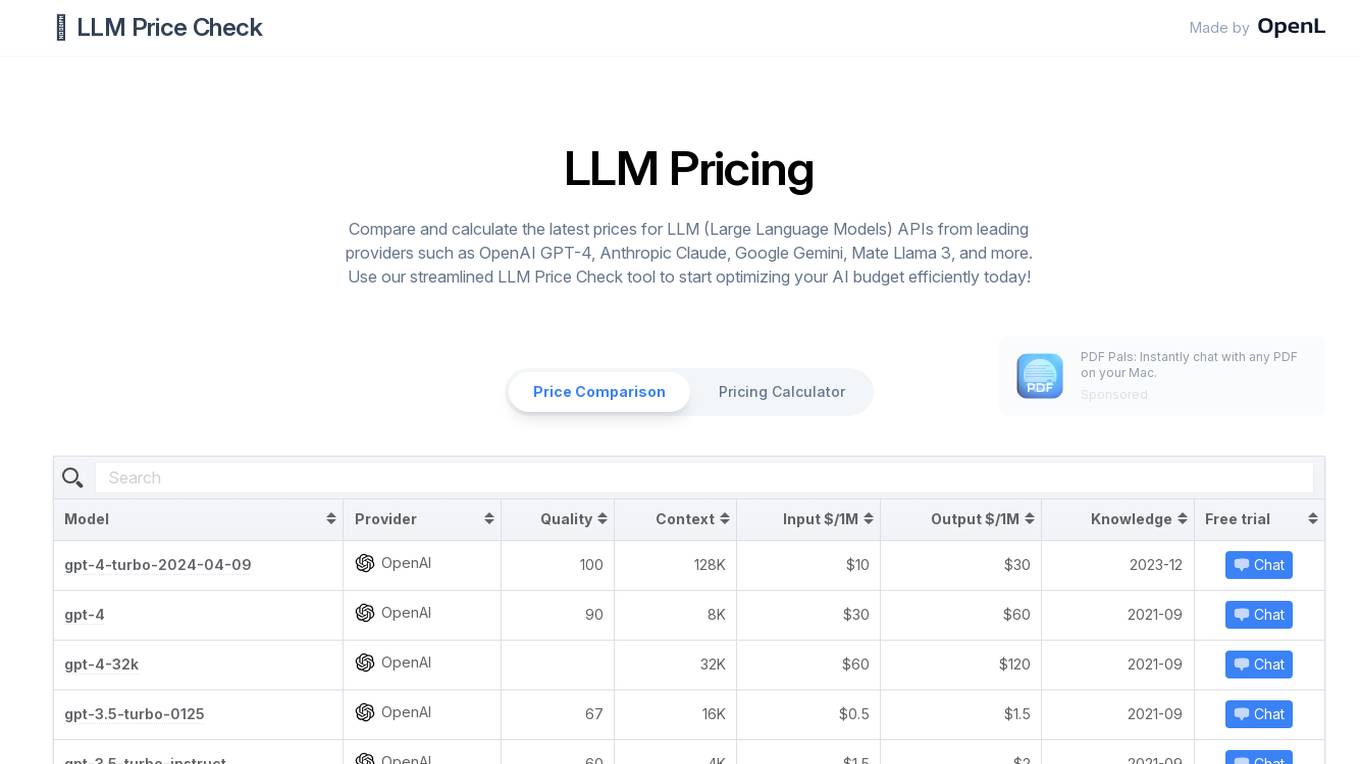
LLM Price Check
LLM Price Check is an AI tool designed to compare and calculate the latest prices for Large Language Models (LLM) APIs from leading providers such as OpenAI, Anthropic, Google, and more. Users can use the streamlined tool to optimize their AI budget efficiently by comparing pricing, sorting by various parameters, and searching for specific models. The tool provides a comprehensive overview of pricing information to help users make informed decisions when selecting an LLM API provider.
LightFeed
LightFeed is an automated news hub powered by LLM technology that allows users to track, filter, and summarize news from any public website. It offers automated daily updates that can be viewed in a browser, email, or RSS format. Users can create their own news hub with a 10-day free trial and no credit card required. LightFeed employs LLMs like GPT-3.5-turbo and Llama 3 to parse, filter, and summarize web pages into structured and readable feeds. The platform also supports customization of news feeds based on user preferences and provides options for automation and scheduling.
Lamini
Lamini is an enterprise-level LLM platform that offers precise recall with Memory Tuning, enabling teams to achieve over 95% accuracy even with large amounts of specific data. It guarantees JSON output and delivers massive throughput for inference. Lamini is designed to be deployed anywhere, including air-gapped environments, and supports training and inference on Nvidia or AMD GPUs. The platform is known for its factual LLMs and reengineered decoder that ensures 100% schema accuracy in the JSON output.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.
Prompt Hippo
Prompt Hippo is an AI tool designed as a side-by-side LLM prompt testing suite to ensure the robustness, reliability, and safety of prompts. It saves time by streamlining the process of testing LLM prompts and allows users to test custom agents and optimize them for production. With a focus on science and efficiency, Prompt Hippo helps users identify the best prompts for their needs.
deepset
deepset is an AI platform that offers enterprise-level products and solutions for AI teams. It provides deepset Cloud, a platform built with Haystack, enabling fast and accurate prototyping, building, and launching of advanced AI applications. The platform streamlines the AI application development lifecycle, offering processes, tools, and expertise to move from prototype to production efficiently. With deepset Cloud, users can optimize solution accuracy, performance, and cost, and deploy AI applications at any scale with one click. The platform also allows users to explore new models and configurations without limits, extending their team with access to world-class AI engineers for guidance and support.
Astra
Astra is a universal API for LLM function calling that supercharges LLMs with integrations using a single line of code. It allows users to conveniently leverage function calling in LLMs with over 2,200 integrations, manage authentication profiles, import tools easily, and enable function calling with any LLM. Astra replaces JSON with a type-safe UI, making integration management simpler. The application extends the capabilities of LLMs without altering their core structure, offering a seamless layer of integrations and function execution.
AnythingLLM
AnythingLLM is an all-in-one AI application designed for everyone. It offers a suite of tools for working with LLM (Large Language Models), documents, and agents in a fully private environment. Users can install AnythingLLM on their desktop for Windows, MacOS, and Linux, enabling flexible one-click installation and secure, fully private operation without internet connectivity. The application supports custom models, including enterprise models like GPT-4, custom fine-tuned models, and open-source models like Llama and Mistral. AnythingLLM allows users to work with various document formats, such as PDFs and word documents, providing tailored solutions with locally running defaults for privacy.

Reflection 70B
Reflection 70B is a next-gen open-source LLM powered by Llama 70B, offering groundbreaking self-correction capabilities that outsmart GPT-4. It provides advanced AI-powered conversations, assists with various tasks, and excels in accuracy and reliability. Users can engage in human-like conversations, receive assistance in research, coding, creative writing, and problem-solving, all while benefiting from its innovative self-correction mechanism. Reflection 70B sets new standards in AI performance and is designed to enhance productivity and decision-making across multiple domains.

Flow AI
Flow AI is an advanced AI tool designed for evaluating and improving Large Language Model (LLM) applications. It offers a unique system for creating custom evaluators, deploying them with an API, and developing specialized LMs tailored to specific use cases. The tool aims to revolutionize AI evaluation and model development by providing transparent, cost-effective, and controllable solutions for AI teams across various domains.
Officely AI
Officely AI is an AI application that offers a platform for users to access and utilize various LLM (Large Language Model) models. Users can let these models interact with each other and integrate seamlessly. The platform provides tools, use cases, channels, and pricing options for users to explore and leverage the power of AI in their processes.

LLM Pulse
LLM Pulse is an AI search visibility tracker designed for the AI chatbot world. It provides real-time monitoring of your brand's presence across various AI search engines, allowing you to track key prompts, analyze citations, understand visibility scores, and dive into detailed responses. The platform offers insights effortlessly, suggesting relevant prompts, comparing your brand against competitors, and soon analyzing brand sentiment. With different pricing plans catering to individuals, growing businesses, large organizations, and enterprises, LLM Pulse aims to help users make strategic decisions in the age of AI.
Langfuse
Langfuse is an AI tool that offers the Langfuse TypeScript SDK v4 for building and debugging LLM (Large Language Models) applications. It provides features such as tracing, prompt management, evaluation, and metrics to enhance the performance of LLM applications. Langfuse is backed by a team of experts and offers integrations with various platforms and SDKs. The tool aims to simplify the development process of complex LLM applications and improve overall efficiency.

Private LLM
Private LLM is a secure, local, and private AI chatbot designed for iOS and macOS devices. It operates offline, ensuring that user data remains on the device, providing a safe and private experience. The application offers a range of features for text generation and language assistance, utilizing state-of-the-art quantization techniques to deliver high-quality on-device AI experiences without compromising privacy. Users can access a variety of open-source LLM models, integrate AI into Siri and Shortcuts, and benefit from AI language services across macOS apps. Private LLM stands out for its superior model performance and commitment to user privacy, making it a smart and secure tool for creative and productive tasks.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.




CISO GPT
Specialized LLM in computer security, acting as a CISO with 20 years of experience, providing precise, data-driven technical responses to enhance organizational security.
NEO - Ultimate AI
I imitate GPT-5 LLM, with advanced reasoning, personalization, and higher emotional intelligence
EmotionPrompt(LLM→人間ver.)
EmotionPrompt手法に基づいて作成していますが、本来の理論とは反対に人間に対してLLMがPromptを投げます。本来の手法の詳細:https://ai-data-base.com/archives/58158
Agent Prompt Generator for LLM's
This GPT generates the best possible LLM-agents for your system prompts. You can also specify the model size, like 3B, 33B, 70B, etc.
DataLearnerAI-GPT
Using OpenLLMLeaderboard data to answer your questions about LLM. For Currently!

Prompt Peerless - Complete Prompt Optimization
Premier AI Prompt Engineer for Advanced LLM Optimization, Enhancing AI-to-AI Interaction and Comprehension. Create -> Optimize -> Revise iteratively
HackMeIfYouCan
Hack Me if you can - I can only talk to you about computer security, software security and LLM security @JacquesGariepy
SSLLMs Advisor
Helps you build logic security into your GPTs custom instructions. Documentation: https://github.com/infotrix/SSLLMs---Semantic-Secuirty-for-LLM-GPTs
Prompt For Me
🪄Prompt一键强化,快速、精准对齐需求,与AI对话更高效。 🧙♂️解锁LLM潜力,让ChatGPT、Claude更懂你,工作快人一步。 🧸你的AI对话伙伴,定制专属需求,轻松开启高品质对话体验
PyRefactor
Refactor python code. Python expert with proficiency in data science, machine learning (including LLM apps), and both OOP and functional programming.
![VitalsGPT [V0.0.2.2] Screenshot](/screenshots_gpts/g-cL1rJdm11.jpg)
VitalsGPT [V0.0.2.2]
Simple CustomGPT built on Vitals Inquiry Case in Malta, aimed to help journalists and citizens navigate the inquiry's large dataset in a neutral, informative fashion. Always cross-reference replies to actual data. Do not rely solely on this LLM for verification of facts.
llm-export
llm-export is a tool for exporting llm models to onnx and mnn formats. It has features such as passing onnxruntime correctness tests, optimizing the original code to support dynamic shapes, reducing constant parts, optimizing onnx models using OnnxSlim for performance improvement, and exporting lora weights to onnx and mnn formats. Users can clone the project locally, clone the desired LLM project locally, and use LLMExporter to export the model. The tool supports various export options like exporting the entire model as one onnx model, exporting model segments as multiple models, exporting model vocabulary to a text file, exporting specific model layers like Embedding and lm_head, testing the model with queries, validating onnx model consistency with onnxruntime, converting onnx models to mnn models, and more. Users can specify export paths, skip optimization steps, and merge lora weights before exporting.
export_llama_to_onnx
Export LLM like llama to ONNX files without modifying transformers modeling_xx_model.py. Supported models include llama (Hugging Face format), Baichuan, Alibaba Qwen 1.5/2, ChatGlm2/ChatGlm3, and Gemma. Usage examples provided for exporting different models to ONNX files. Various arguments can be used to configure the export process. Note on uninstalling/disabling FlashAttention and xformers before model conversion. Recommendations for handling kv_cache format and simplifying large ONNX models. Disclaimer regarding correctness of exported models and consequences of usage.
llm-course
The llm-course repository is a collection of resources and materials for a course on Legal and Legislative Drafting. It includes lecture notes, assignments, readings, and other educational materials to help students understand the principles and practices of drafting legal documents. The course covers topics such as statutory interpretation, legal drafting techniques, and the role of legislation in the legal system. Whether you are a law student, legal professional, or someone interested in understanding the intricacies of legal language, this repository provides valuable insights and resources to enhance your knowledge and skills in legal drafting.

Native-LLM-for-Android
This repository provides a demonstration of running a native Large Language Model (LLM) on Android devices. It supports various models such as Qwen2.5-Instruct, MiniCPM-DPO/SFT, Yuan2.0, Gemma2-it, StableLM2-Chat/Zephyr, and Phi3.5-mini-instruct. The demo models are optimized for extreme execution speed after being converted from HuggingFace or ModelScope. Users can download the demo models from the provided drive link, place them in the assets folder, and follow specific instructions for decompression and model export. The repository also includes information on quantization methods and performance benchmarks for different models on various devices.

llm-foundry
LLM Foundry is a codebase for training, finetuning, evaluating, and deploying LLMs for inference with Composer and the MosaicML platform. It is designed to be easy-to-use, efficient _and_ flexible, enabling rapid experimentation with the latest techniques. You'll find in this repo: * `llmfoundry/` - source code for models, datasets, callbacks, utilities, etc. * `scripts/` - scripts to run LLM workloads * `data_prep/` - convert text data from original sources to StreamingDataset format * `train/` - train or finetune HuggingFace and MPT models from 125M - 70B parameters * `train/benchmarking` - profile training throughput and MFU * `inference/` - convert models to HuggingFace or ONNX format, and generate responses * `inference/benchmarking` - profile inference latency and throughput * `eval/` - evaluate LLMs on academic (or custom) in-context-learning tasks * `mcli/` - launch any of these workloads using MCLI and the MosaicML platform * `TUTORIAL.md` - a deeper dive into the repo, example workflows, and FAQs
mnn-llm
MNN-LLM is a high-performance inference engine for large language models (LLMs) on mobile and embedded devices. It provides optimized implementations of popular LLM models, such as ChatGPT, BLOOM, and GPT-3, enabling developers to easily integrate these models into their applications. MNN-LLM is designed to be efficient and lightweight, making it suitable for resource-constrained devices. It supports various deployment options, including mobile apps, web applications, and embedded systems. With MNN-LLM, developers can leverage the power of LLMs to enhance their applications with natural language processing capabilities, such as text generation, question answering, and dialogue generation.
llm-apps-java-spring-ai
The 'LLM Applications with Java and Spring AI' repository provides samples demonstrating how to build Java applications powered by Generative AI and Large Language Models (LLMs) using Spring AI. It includes projects for question answering, chat completion models, prompts, templates, multimodality, output converters, embedding models, document ETL pipeline, function calling, image models, and audio models. The repository also lists prerequisites such as Java 21, Docker/Podman, Mistral AI API Key, OpenAI API Key, and Ollama. Users can explore various use cases and projects to leverage LLMs for text generation, vector transformation, document processing, and more.
turnkeyml
TurnkeyML is a tools framework that integrates models, toolchains, and hardware backends to simplify the evaluation and actuation of deep learning models. It supports use cases like exporting ONNX files, performance validation, functional coverage measurement, stress testing, and model insights analysis. The framework consists of analysis, build, runtime, reporting tools, and a models corpus, seamlessly integrated to provide comprehensive functionality with simple commands. Extensible through plugins, it offers support for various export and optimization tools and AI runtimes. The project is actively seeking collaborators and is licensed under Apache 2.0.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
RealtimeSTT_LLM_TTS
RealtimeSTT is an easy-to-use, low-latency speech-to-text library for realtime applications. It listens to the microphone and transcribes voice into text, making it ideal for voice assistants and applications requiring fast and precise speech-to-text conversion. The library utilizes Voice Activity Detection, Realtime Transcription, and Wake Word Activation features. It supports GPU-accelerated transcription using PyTorch with CUDA support. RealtimeSTT offers various customization options for different parameters to enhance user experience and performance. The library is designed to provide a seamless experience for developers integrating speech-to-text functionality into their applications.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
Building-a-Small-LLM-from-Scratch
This tutorial provides a comprehensive guide on building a small Large Language Model (LLM) from scratch using PyTorch. The author shares insights and experiences gained from working on LLM projects in the industry, aiming to help beginners understand the fundamental components of LLMs and training fine-tuning codes. The tutorial covers topics such as model structure overview, attention modules, optimization techniques, normalization layers, tokenizers, pretraining, and fine-tuning with dialogue data. It also addresses specific industry-related challenges and explores cutting-edge model concepts like DeepSeek network structure, causal attention, dynamic-to-static tensor conversion for ONNX inference, and performance optimizations for NPU chips. The series emphasizes hands-on practice with small models to enable local execution and plans to expand into multimodal language models and tensor parallel multi-card deployment.
ASR-LLM-TTS
ASR-LLM-TTS is a repository that provides detailed tutorials for setting up the environment, including installing anaconda, ffmpeg, creating virtual environments, and installing necessary libraries such as pytorch, torchaudio, edge-tts, funasr, and more. It also introduces features like voiceprint recognition, custom wake words, and conversation history memory. The repository combines CosyVoice for speech synthesis, SenceVoice for speech recognition, and QWen2.5 for dialogue understanding. It offers multiple speech synthesis methods including CoosyVoice, pyttsx3, and edgeTTS, with scripts for interactive inference provided. The repository aims to enable real-time speech interaction and multi-modal interactions involving audio and video.
TensorRT-LLM
TensorRT-LLM is an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM contains components to create Python and C++ runtimes that execute those TensorRT engines. It also includes a backend for integration with the NVIDIA Triton Inference Server; a production-quality system to serve LLMs. Models built with TensorRT-LLM can be executed on a wide range of configurations going from a single GPU to multiple nodes with multiple GPUs (using Tensor Parallelism and/or Pipeline Parallelism).
rank_llm
RankLLM is a suite of prompt-decoders compatible with open source LLMs like Vicuna and Zephyr. It allows users to create custom ranking models for various NLP tasks, such as document reranking, question answering, and summarization. The tool offers a variety of features, including the ability to fine-tune models on custom datasets, use different retrieval methods, and control the context size and variable passages. RankLLM is easy to use and can be integrated into existing NLP pipelines.
Awesome-LLM-Compression
Awesome LLM compression research papers and tools to accelerate LLM training and inference.

Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.